Knowledge
- Identify the three admission control policies for HA
- Identify heartbeat options and dependencies
Skills and Abilities
- Calculate host failure requirements
- Configure customized isolation response settings
-
Configure HA redundancy
- Management Network
- Datastore Heartbeat
- Network partitions
- Configure HA related alarms and monitor an HA cluster
- Create a custom slot size configuration
- Understand interactions between DRS and HA
- Analyze vSphere environment to determine appropriate HA admission control policy
- Analyze performance metrics to calculate host failure requirements
- Analyze Virtual Machine workload to determine optimum slot size
- Analyze HA cluster capacity to determine optimum cluster size
Calculate host failure requirements
Official Documentation:
vSphere Availability Guide, Chapter 2, Section “Host Failures Cluster Tolerates Admission Control Policy”, page 18.
You can configure vSphere HA to tolerate a specified number of host failures. With the Host Failures Cluster Tolerates admission control policy, vSphere HA ensures that a specified number of hosts can fail and sufficient resources remain in the cluster to fail over all the virtual machines from those hosts.
With the Host Failures Cluster Tolerates policy, vSphere HA performs admission control in the following way:
- Calculates the slot size. A slot is a logical representation of memory and CPU resources. By default, it is sized to satisfy the requirements for any powered-on virtual machine in the cluster.
- Determines how many slots each host in the cluster can hold.
- Determines the Current Failover Capacity of the cluster. This is the number of hosts that can fail and still leave enough slots to satisfy all of the powered-on virtual machines.
- Determines whether the Current Failover Capacity is less than the Configured Failover Capacity (provided by the user). If it is, admission control disallows the operation.
Slot Size Calculation
Slot size is comprised of two components, CPU and memory.
- vSphere HA calculates the CPU component by obtaining the CPU reservation of each powered-on virtual machine and selecting the largest value. If you have not specified a CPU reservation for a virtual machine, it is assigned a default value of 32MHz. You can change this value by using the das.vmcpuminmhz advanced attribute.)
- vSphere HA calculates the memory component by obtaining the memory reservation, plus memory overhead, of each powered-on virtual machine and selecting the largest value. There is no default value for the memory reservation.
If your cluster contains any virtual machines that have much larger reservations than the others, they will distort slot size calculation. To avoid this, you can specify an upper bound for the CPU or memory component of the slot size by using the das.slotcpuinmhz or das.slotmeminmb advanced attributes, respectively. See “vSphere HA Advanced Attributes,” on page 30.
Using Slots to Compute the Current Failover Capacity
After the slot size is calculated, vSphere HA determines each host’s CPU and memory resources that are available for virtual machines. These amounts are those contained in the host’s root resource pool, not the total physical resources of the host. The resource data for a host that is used by vSphere HA can be found by using the vSphere Client to connect to the host directly, and then navigating to the Resource tab for the host. If all hosts in your cluster are the same, this data can be obtained by dividing the cluster-level figures by the number of hosts. Resources being used for virtualization purposes are not included. Only hosts that are connected, not in maintenance mode, and that have no vSphere HA errors are considered.
The maximum number of slots that each host can support is then determined. To do this, the host’s CPU resource amount is divided by the CPU component of the slot size and the result is rounded down. The same calculation is made for the host’s memory resource amount. These two numbers are compared and the smaller number is the number of slots that the host can support.
The Current Failover Capacity is computed by determining how many hosts (starting from the largest) can fail and still leave enough slots to satisfy the requirements of all powered-on virtual machines.
Advanced Runtime Info
When you select the Host Failures Cluster Tolerates admission control policy, the Advanced Runtime Info link appears in the vSphere HA section of the cluster’s Summary tab in the vSphere Client. Click this link to display the following information about the cluster:
- Slot size.
- Total slots in cluster. The sum of the slots supported by the good hosts in the cluster.
- Used slots. The number of slots assigned to powered-on virtual machines. It can be more than the number of powered-on virtual machines if you have defined an upper bound for the slot size using the advanced options. This is because some virtual machines can take up multiple slots.
- Available slots. The number of slots available to power on additional virtual machines in the cluster.
- vSphere HA reserves the required number of slots for failover. The remaining slots are available to power on new virtual machines.
- Failover slots. The total number of slots not counting the used slots or the available slots.
- Total number of powered on virtual machines in cluster.
- Total number of hosts in cluster.
- Total number of good hosts in cluster. The number of hosts that are connected, not in maintenance mode, and have no vSphere HA errors.
Example: Admission Control Using Host Failures Cluster Tolerates Policy
The way that slot size is calculated and used with this admission control policy is shown in an example. Make the following assumptions about a cluster:
- The cluster is comprised of three hosts, each with a different amount of available CPU and memory resources. The first host (H1) has 9GHz of available CPU resources and 9GB of available memory, while Host 2 (H2) has 9GHz and 6GB and Host 3 (H3) has 6GHz and 6GB.
- There are five powered-on virtual machines in the cluster with differing CPU and memory requirements. VM1 needs 2GHz of CPU resources and 1GB of memory, while VM2 needs 2GHz and 1GB, VM3 needs 1GHz and 2GB, VM4 needs 1GHz and 1GB, and VM5 needs 1GHz and 1GB.
- The Host Failures Cluster Tolerates is set to one.
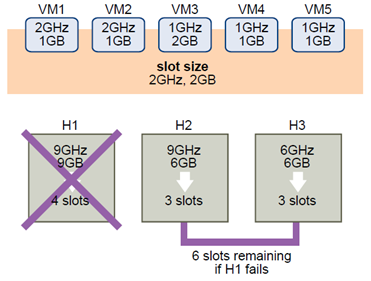
- Slot size is calculated by comparing both the CPU and memory requirements of the virtual machines and selecting the largest. The largest CPU requirement (shared by VM1 and VM2) is 2GHz, while the largest memory requirement (for VM3) is 2GB. Based on this, the slot size is 2GHz CPU and 2GB memory.
- Maximum number of slots that each host can support is determined. H1 can support four slots. H2 can support three slots (which is the smaller of 9GHz/2GHz and 6GB/2GB) and H3 can also support three slots.
- Current Failover Capacity is computed. The largest host is H1 and if it fails, six slots remain in the cluster, which is sufficient for all five of the powered-on virtual machines. If both H1 and H2 fail, only three slots remain, which is insufficient.
Therefore, the Current Failover Capacity is one. The cluster has one available slot (the six slots on H2 and H3 minus the five used slots).
Configure customized isolation response settings
Official Documentation:
vSphere Availability Guide Chapter 2, Section “Host Isolation Response Setting”, page 28.
Host Isolation Response Setting
Host isolation response determines what happens when a host in a vSphere HA cluster loses its management network connections but continues to run. Host isolation responses require that Host Monitoring Status is enabled. If Host Monitoring Status is disabled, host isolation responses are also suspended. A host determines that it is isolated when it is unable to communicate with the agents running on the other hosts and it is unable to ping its isolation addresses. When this occurs, the host executes its isolation response. The responses are:
Leave powered on (the default), Power off, and Shut down. You can customize this property for individual virtual machines.
To use the Shut down VM setting, you must install VMware Tools in the guest operating system of the virtual machine. Shutting down the virtual machine provides the advantage of preserving its state. Shutting down is better than powering off the virtual machine, which does not flush most recent changes to disk or commit transactions. Virtual machines that are in the process of shutting down will take longer to fail over while the shutdown completes. Virtual Machines that have not shut down in 300 seconds, or the time specified in the advanced attribute das.isolationshutdowntimeout seconds, are powered off.
NOTE After you create a vSphere HA cluster, you can override the default cluster settings for Restart Priority and Isolation Response for specific virtual machines. Such overrides are useful for virtual machines that are used for special tasks. For example, virtual machines that provide infrastructure services like DNS or DHCP might need to be powered on before other virtual machines in the cluster.
If a host has its isolation response disabled (that is, it leaves virtual machines powered on when isolated) and the host loses access to both the management and storage networks, a “split brain” situation can arise. In this case, the isolated host loses the disk locks and the virtual machines are failed over to another host even though the original instances of the virtual machines remain running on the isolated host. When the host comes out of isolation, there will be two copies of the virtual machines, although the copy on the originally isolated host does not have access to the vmdk files and data corruption is prevented. In the vSphere Client, the virtual machines appear to be flipping back and forth between the two hosts.
To recover from this situation, ESXi generates a question on the virtual machine that has lost the disk locks for when the host comes out of isolation and realizes that it cannot reacquire the disk locks. vSphere HA automatically answers this question and this allows the virtual machine instance that has lost the disk locks to power off, leaving just the instance that has the disk locks.
Configure HA redundancy
Official Documentation:
vSphere High Availability Deployment Best Practices
vSphere HA Checklist
The vSphere HA checklist contains requirements that you need to be aware of before creating and using a vSphere HA cluster.
Requirements for a vSphere HA Cluster
Review this list before setting up a vSphere HA cluster. For more information, follow the appropriate cross reference or see “Creating a vSphere HA Cluster,” on page 25.
- All hosts must be licensed for vSphere HA.
NOTE ESX/ESXi 3.5 hosts are supported by vSphere HA but must include a patch to address an issue involving file locks. For ESX 3.5 hosts, you must apply the patch ESX350-201012401-SG, while for ESXi 3.5 you must apply the patch ESXe350-201012401-I-BG. Prerequisite patches need to be applied before applying these patches. - You need at least two hosts in the cluster.
- All hosts need to be configured with static IP addresses. If you are using DHCP, you must ensure that the address for each host persists across reboots.
-
There should be at least one management network in common among all hosts and best practice is to have at least two. Management networks differ depending on the version of host you are using.
- ESX hosts – service console network.
- ESXi hosts earlier than version 4.0 – VMkernel network.
- ESXi hosts version 4.0 and later ESXi hosts – VMkernel network with the Management Network checkbox enabled.
See “Best Practices for Networking,” on page 34.
- To ensure that any virtual machine can run on any host in the cluster, all hosts should have access to the same virtual machine networks and datastores. Similarly, virtual machines must be located on shared, not local, storage otherwise they cannot be failed over in the case of a host failure.
NOTE vSphere HA uses datastore heartbeating to distinguish between partitioned, isolated, and failed hosts. Accordingly, you must ensure that datastores reserved for vSphere HA are readily available at all times. - For VM Monitoring to work, VMware tools must be installed. See “VM and Application Monitoring,” on page 28.
- Host certificate checking should be enabled. See “Enable Host Certificate Checking,” on page 43.
- vSphere HA supports both IPv4 and IPv6. A cluster that mixes the use of both of these protocol versions, however, is more likely to result in a network partition.
Design Principles for High Availability
The key to architecting a highly available computing environment is to eliminate single points of failure. With the potential of occurring anywhere in the environment, failures can affect both hardware and software. Building redundancy at vulnerable points helps reduce or eliminate downtime caused by [implied] hardware failures.
These include redundancies at the following layers:
- Server components such as network adaptors and host bus adaptors (HBAs)
- Servers, including blades and blade chassis
- Networking components
- Storage arrays and storage networking
Host Considerations
Prior planning regarding hosts to be used in a cluster will provide the best results. Because it is not always possible to start with a greenfield environment, this section will discuss some of the considerations applicable to the hosts.
Host Selection
Overall vSphere availability starts with proper host selection. This includes items such as redundant power supplies, error-correcting memory, remote monitoring and notification, and so on. Consideration should also be given to removing single points of failure in host location. This includes distributing hosts across multiple racks or blade chassis to remove the ability for rack or chassis failure to impact an entire cluster.
When deploying a VMware HA cluster, it is a best practice to build the cluster out of identical server hardware.
Using identical hardware provides a number of key advantages, such as the following ones:
- Simplifies configuration and management of the servers using Host Profiles
- Increases ability to handle server failures and reduces resource fragmentation. Using drastically different hardware will lead to an unbalanced cluster, as described in the “Admission Control” section. By default, HA prepares for the worst-case scenario in that the largest host in the cluster could fail. To handle the worst case, more resources across all hosts must be reserved, making them essentially unusable.
The overall size of a cluster is another important factor to consider. Smaller-sized clusters require a larger relative percentage of the available cluster resources to be set aside as reserve capacity to adequately handle failures.
Host Versioning
An ideal configuration is one where all the hosts contained within the cluster use the latest version of ESXi.
When adding a host to vSphere 5.0 clusters, it is always a best practice to upgrade the host to ESXi 5.0 and to avoid using clusters with mixed-host versions.
Upgrading hosts to ESXi 5.0 enables users to utilize features that were not supported for earlier host versions and to leverage capabilities that have been improved. A good example of this is the support added in vSphere 5.0 for management network partitions. This feature is supported only if the cluster contains only ESXi 5.0 hosts.
Mixed clusters are supported but not recommended because there are some differences in VMware HA performance between host versions, and these differences can introduce operational variances in a cluster.
Host Placement
In versions of vSphere prior to 5.0, the concept of primary and secondary hosts, with a limit of five primary hosts, was present. This construct was the focus of many best-practice recommendations. In vSphere High Availability 5.0, this construct has been eliminated. Instead, VMware HA now uses a master/slave relationship between the nodes of a cluster. Under normal operations, there will be a single host that takes on the role of the master. All other hosts are referred to as slave hosts. In the event of a failure of a host acting as a master, an election process is performed and a new master is selected.
The use of this new construct for HA eliminates concerns held previously regarding the following issues:
- Number of hosts in a cluster
- Managing the role of the host
- Number of consecutive host failures
- Placement of hosts across blade chassis and stretched clusters
- Partition scenarios likely to occur in stretched cluster environments
Networking Design Considerations
Best practices network design falls into two specific areas, increasing resiliency of “client-side” networking to ensure access from external systems to workloads running in vSphere, and increasing resiliency of communications used by HA itself.
General Networking Guidelines
The following suggestions are best practices for configuring networking in general for improved availability:
- Configuring switches. If the physical network switches that connect your servers support the PortFast (or an equivalent) setting, enable it. This setting prevents a host from incorrectly determining that a network is isolated during the execution of lengthy spanning tree algorithms on boot. For more information on this option, refer to the documentation provided by your networking switch vendor.
- Disable host monitoring when performing any network maintenance that might disable all heartbeat paths (including storage heartbeats) between the hosts within the cluster, because this might trigger an isolation response.
- With vSphere High Availability 5.0, all dependencies on DNS have been removed, making previous best practices of updating DNS for the purpose of HA irrelevant. However, it is always a best practice to ensure that the hosts and virtual machines within an environment are able to be properly resolved through DNS.
- Use consistent port names on VLANs for virtual machine networks on all ESXi hosts in the cluster. Port names are used to determine compatibility of the network by virtual machines. Before initiating a failover, HA will check whether a host is compatible. If there are no hosts with matching port group names available, no failover is possible. Use of a documented naming scheme is highly recommended. Issues with port naming can be completely mitigated by using vSphere distributed virtual switches.
- In environments where both IPv4 and IPv6 protocols are used, configure the virtual switches on all hosts to enable access to both networks. This prevents network partition issues due to the loss of a single IP networking stack or host failure.
- Ensure that TCP/UDP port 8182 is open within the network. HA will automatically open these ports when enabled and close when disabled. User action is required only if there are firewalls in place between hosts within the cluster, as in a stretched cluster configuration.
- If using an ESX host, ensure that there is no service running in the ESX console OS that uses port 8182.
- Configure redundant management networking from ESXi hosts to network switching hardware if possible. Using network adaptor teaming can enhance overall network availability as well as increase overall throughput.
- In configurations with multiple management networks, an isolation address must be configured for each network. Refer to the “Host Isolation” section for more details.
Network Adaptor Teaming and Management Networks
Using a team of two network adaptors connected to separate physical switches can improve the reliability of the management network. Because servers connected to each other through two network adaptors, and through separate switches, have two independent paths for cluster communication, the cluster is more resilient to failures.
To configure a network adaptor team for the management network, configure the vNICs in the vSwitch configuration for the ESXi host for active/standby configuration.
Requirements:
- Two physical network adaptors
- VLAN trunking
- Two physical switches
Storage Design Considerations
To maintain a constant connection between an ESXi host and its storage, ESXi supports multipathing, a technique that enables you to use more than one physical path to transfer data between the host and an external storage device.
In case of a failure of any element in the SAN network, such as an adapter, switch or cable, ESXi can move to another physical path that does not use the failed component. This process of path switching to avoid failed components is known as path failover.
In addition to path failover, multipathing provides load balancing, the process of distributing I/O loads across multiple physical paths. Load balancing reduces or removes potential bottlenecks.
Cluster Configuration Considerations
Many options are available when configuring a vSphere High Availability environment. This flexibility enables users to leverage HA in a wide range of environments while accommodating particular requirements. In this section, we will discuss some of the key cluster configuration options and the recommended best practices for them.
Configure HA related alarms and monitor an HA cluster
Official Documentation:
vSphere Availability Guide, page 32
When vSphere HA or Fault Tolerance take action to maintain availability, for example, a virtual machine failover, you can be notified about such changes. Configure alarms in vCenter Server to be triggered when these actions occur, and have alerts, such as emails, sent to a specified set of administrators.
Several default vSphere HA alarms are available.
- Insufficient failover resources (a cluster alarm)
- Cannot find master (a cluster alarm)
- Failover in progress (a cluster alarm)
- Host HA status (a host alarm)
- VM monitoring error (a virtual machine alarm)
- VM monitoring action (a virtual machine alarm)
- Failover failed (a virtual machine alarm)
NOTE The default alarms include the feature name, vSphere HA.
Monitoring Cluster Validity
A valid cluster is one in which the admission control policy has not been violated.
A cluster enabled for vSphere HA becomes invalid (red) when the number of virtual machines powered on exceeds the failover requirements, that is, the current failover capacity is smaller than configured failover capacity. If admission control is disabled, clusters do not become invalid.
The cluster’s Summary tab in the vSphere Client displays a list of configuration issues for clusters. The list explains what has caused the cluster to become invalid or overcommitted (yellow).
DRS behavior is not affected if a cluster is red because of a vSphere HA issue.
Create a custom slot size configuration
Official Documentation:
vSphere Availability Guide, Page 17 and 28
If your cluster contains any virtual machines that have much larger reservations than the others, they will distort slot size calculation. To avoid this, you can specify an upper bound for the CPU or memory component of the slot size by using the das.slotcpuinmhz or das.slotmeminmb advanced attributes, respectively. See “vSphere HA Advanced Attributes,” on page 30.
vSphere HA Advanced Attributes
You can set advanced attributes that affect the behavior of your vSphere HA cluster.
| Attribute | Description |
| das.isolationaddress[…] | Sets the address to ping to determine if a host is isolated fromthe network. This address is pinged only when heartbeats arenot received from any other host in the cluster. If not
specified, the default gateway of the management network is used. This default gateway has to be a reliable address that is available, so that the host can determine if it is isolated from the network. You can specify multiple isolation addresses (up to 10) for the cluster: das.isolationaddressX, where X = 1-10. Typically you should specify one per management network. Specifying too many addresses makes isolation detection take too long. |
| das.usedefaultisolationaddress | By default, vSphere HA uses the default gateway of theconsole network as an isolation address. This attributespecifies whether or not this default is used (true|false). |
| das.isolationshutdowntimeout | The period of time the system waits for a virtual machine toshut down before powering it off. This only applies if thehost’s isolation response is Shut down VM. Default value is
300 seconds. |
| das.slotmeminmb | Defines the maximum bound on the memory slot size. If thisoption is used, the slot size is the smaller of this value or themaximum memory reservation plus memory overhead of
any powered-on virtual machine in the cluster. |
| das.slotcpuinmhz | Defines the maximum bound on the CPU slot size. If thisoption is used, the slot size is the smaller of this value or themaximum CPU reservation of any powered-on virtual
machine in the cluster. |
| das.vmmemoryminmb | Defines the default memory resource value assigned to avirtual machine if its memory reservation is not specified orzero. This is used for the Host Failures Cluster Tolerates
admission control policy. If no value is specified, the default is 0 MB. |
| das.vmcpuminmhz | Defines the default CPU resource value assigned to a virtualmachine if its CPU reservation is not specified or zero. Thisis used for the Host Failures Cluster Tolerates admission
control policy. If no value is specified, the default is 32MHz. |
| das.iostatsinterval | Changes the default I/O stats interval for VM Monitoringsensitivity. The default is 120 (seconds). Can be set to anyvalue greater than, or equal to 0. Setting to 0 disables the
check. |
| das.ignoreinsufficienthbdatastore | Disables configuration issues created if the host does nothave sufficient heartbeat datastores for vSphere HA. Defaultvalue is false. |
| das.heartbeatdsperhost | Changes the number of heartbeat datastores required. Validvalues can range from 2-5 and the default is 2. |
NOTE If you change the value of any of the following advanced attributes, you must disable and then re-enable vSphere HA before your changes take effect.
- das.isolationaddress[…]
- das.usedefaultisolationaddress
- das.isolationshutdowntimeout
Understand interactions between DRS and HA
Official Documentation:
vSphere Availability Guide, page 17
Using vSphere HA with Distributed Resource Scheduler (DRS) combines automatic failover with load balancing. This combination can result in a more balanced cluster after vSphere HA has moved virtual machines to different hosts.
When vSphere HA performs failover and restarts virtual machines on different hosts, its first priority is the immediate availability of all virtual machines. After the virtual machines have been restarted, those hosts on which they were powered on might be heavily loaded, while other hosts are comparatively lightly loaded.
vSphere HA uses the virtual machine’s CPU and memory reservation to determine if a host has enough spare capacity to accommodate the virtual machine.
In a cluster using DRS and vSphere HA with admission control turned on, virtual machines might not be evacuated from hosts entering maintenance mode. This behavior occurs because of the resources reserved for restarting virtual machines in the event of a failure. You must manually migrate the virtual machines off of the hosts using vMotion.
In some scenarios, vSphere HA might not be able to fail over virtual machines because of resource constraints.
This can occur for several reasons.
- HA admission control is disabled and Distributed Power Management (DPM) is enabled. This can result in DPM consolidating virtual machines onto fewer hosts and placing the empty hosts in standby mode leaving insufficient powered-on capacity to perform a failover.
- VM-Host affinity (required) rules might limit the hosts on which certain virtual machines can be placed.
- There might be sufficient aggregate resources but these can be fragmented across multiple hosts so that they cannot be used by virtual machines for failover.
In such cases, vSphere HA can use DRS to try to adjust the cluster (for example, by bringing hosts out of standby mode or migrating virtual machines to defragment the cluster resources) so that HA can perform the failovers.
If DPM is in manual mode, you might need to confirm host power-on recommendations. Similarly, if DRS is in manual mode, you might need to confirm migration recommendations.
If you are using VM-Host affinity rules that are required, be aware that these rules cannot be violated. vSphere HA does not perform a failover if doing so would violate such a rule.
Analyze vSphere environment to determine appropriate HA admission control policy
Official Documentation:
vSphere Availability Guide, page 23.
You should choose a vSphere HA admission control policy based on your availability needs and the characteristics of your cluster. When choosing an admission control policy, you should consider a number of factors.
Avoiding Resource Fragmentation
Resource fragmentation occurs when there are enough resources in aggregate for a virtual machine to be failed over. However, those resources are located on multiple hosts and are unusable because a virtual machine can run on one ESXi host at a time. The Host Failures Cluster Tolerates policy avoids resource fragmentation by defining a slot as the maximum virtual machine reservation. The Percentage of Cluster Resources policy does not address the problem of resource fragmentation. With the Specify Failover Hosts policy, resources are not fragmented because hosts are reserved for failover.
Flexibility of Failover Resource Reservation
Admission control policies differ in the granularity of control they give you when reserving cluster resources for failover protection. The Host Failures Cluster Tolerates policy allows you to set the failover level as a number of hosts. The Percentage of Cluster Resources policy allows you to designate up to 100% of cluster CPU or memory resources for failover. The Specify Failover Hosts policy allows you to specify a set of failover hosts.
Heterogeneity of Cluster
Clusters can be heterogeneous in terms of virtual machine resource reservations and host total resource capacities. In a heterogeneous cluster, the Host Failures Cluster Tolerates policy can be too conservative because it only considers the largest virtual machine reservations when defining slot size and assumes the largest hosts fail when computing the Current Failover Capacity. The other two admission control policies are not affected by cluster heterogeneity.
NOTE vSphere HA includes the resource usage of Fault Tolerance Secondary VMs when it performs admission control calculations. For the Host Failures Cluster Tolerates policy, a Secondary VM is assigned a slot, and for the Percentage of Cluster Resources policy, the Secondary VM’s resource usage is accounted for when computing the usable capacity of the cluster.
Analyze performance metrics to calculate host failure requirements
Official Documentation:
vSphere Availability Guide
Even on the Cluster level is a Performance tab available. In the Overview mode, three views are available:
- Home (CPU and Memory metrics on the Cluster level)
- Resource Pools & Virtual Machines (Detailed CPU and Memory metrics on RP, ESXi host and VM level)
- Hosts (Detailed CPU and Memory metrics per ESXi host)
The Advanced View has a section on Cluster Services. Three metrics are available, from which two can be selected at a time:
- Effective CPU resources, Total available CPU resources of all hosts within a cluster;
- Effective Memory resources, Total amount of machine memory of all hosts in the cluster that is available for use for the VM memory and overhead memory;
- Current Failover level, the vSphere HA number of failures that can be tolerated.
The last metric is a good indication.
Analyze Virtual Machine workload to determine optimum slot size
Official Documentation:
vSphere Availability Guide
See first topic. Slot Size is part of the “Host failure Cluster Tolerates ” admission control policy. The slot size is compromised of two components, CPU and Memory. CPU and Memory Reservations do have a huge impact on the calculated slot size.
Analyze HA cluster capacity to determine optimum cluster size
Official Documentation:
vSphere Availability Guide
See the previous two topics. Other guidelines can be found in the vSphere Availability Guide Deployment Best Practices.
- Cluster size, minimum # hosts is 2, maximum is 32.
- Build cluster of identical servers, otherwise consider building multiple clusters of identical servers
- Smaller-sized clusters require a larger relative percentage of the available cluster resources to be set aside as reserve capacity to adequately handle failures.
For example, for a cluster of three nodes to tolerate a single host failure, about 33 percent of the cluster resources will be reserved for failover. A 10-node cluster requires that only 10 percent be reserved. - As cluster size increases, so does the HA management complexity of the cluster. This complexity is associated with general configuration factors as well as ongoing management tasks such as troubleshooting. This increase in management complexity, however, is overshadowed by the benefits a large cluster can provide. Features such as DRS and Distributed Power Management (DPM) become very compelling with large clusters. In general, it is recommended that creating the largest clusters possible to reap the full benefits of these solutions.
- If possible, all hosts in a cluster run the same and the latest edition of ESXi. Otherwise read the guidelines if you have a mixed Cluster.
Other references:
- In case you want to check your Cluster Capacity using PowerShell, read this post by Jonathan Medd.
Other exam notes
- The Saffageek VCAP5-DCA Objectives http://thesaffageek.co.uk/vcap5-dca-objectives/
- Paul Grevink The VCAP5-DCA diaries http://paulgrevink.wordpress.com/the-vcap5-dca-diaries/
- Edward Grigson VCAP5-DCA notes http://www.vexperienced.co.uk/vcap5-dca/
- Jason Langer VCAP5-DCA notes http://www.virtuallanger.com/vcap-dca-5/
- The Foglite VCAP5-DCA notes http://thefoglite.com/vcap-dca5-objective/
Books
- Duncan Epping and Frank Denneman, VMware vSphere 5.0 Clustering Technical Deepdive.
- Duncan Epping and Frank Denneman, VMware vSphere 5.1 Clustering Deepdive.
VMware vSphere official documentation
| VMware vSphere Basics Guide | html | epub | mobi | |
| vSphere Installation and Setup Guide | html | epub | mobi | |
| vSphere Upgrade Guide | html | epub | mobi | |
| vCenter Server and Host Management Guide | html | epub | mobi | |
| vSphere Virtual Machine Administration Guide | html | epub | mobi | |
| vSphere Host Profiles Guide | html | epub | mobi | |
| vSphere Networking Guide | html | epub | mobi | |
| vSphere Storage Guide | html | epub | mobi | |
| vSphere Security Guide | html | epub | mobi | |
| vSphere Resource Management Guide | html | epub | mobi | |
| vSphere Availability Guide | html | epub | mobi | |
| vSphere Monitoring and Performance Guide | html | epub | mobi | |
| vSphere Troubleshooting | html | epub | mobi | |
| VMware vSphere Examples and Scenarios Guide | html | epub | mobi |
Disclaimer.
The information in this article is provided “AS IS” with no warranties, and confers no rights. This article does not represent the thoughts, intentions, plans or strategies of my employer. It is solely my opinion.